Le choix des tireurs de penalty par l’Angleterre lors de la finale de l’Euro2020 est l’exemple le plus récent de mauvaise décision prise après la suggestion d’un algorithme.
 L’entraîneur Southgate a révélé qu’il avait choisi les joueurs et leur ordre sur la base des sorties d’algorithmes d’« intelligence artificielle » (IA) ;
L’entraîneur Southgate a révélé qu’il avait choisi les joueurs et leur ordre sur la base des sorties d’algorithmes d’« intelligence artificielle » (IA) ;
Malheureusement, trois d’entre eux n’ont pas réussi à marquer leur penalty et l’Angleterre a perdu la coupe d’Europe face à l’Italie.
Bien sûr, il n’y avait aucun moyen de juger cette décision « mauvaise » avant le début des tirs au but ; néanmoins, cela nous rappelle que les prédictions, suggestions et décisions basées sur des données sont intrinsèquement probabilistes et comportent parfois de grandes incertitudes. Cela devrait mettre en garde contre les lacunes potentielles en matière de responsabilité.

Les outputs des algorithmes d’IA actuels sont intrinsèquement probabilistes, pour plusieurs raisons.
Pour commencer, le fait d’injecter un certain degré d’aléatoire dans les algorithmes aide à rendre leur output plus général et utile.
De plus, l’architecture informatique comprend généralement – par conception – une fonction mathématique qui convertit tous les calculs précédents en une sortie de probabilité. Une image est classée comme « chat » s’il est hautement probable que la machine classe ce qui est traité comme un ensemble de caractéristiques qui appartenaient auparavant aux chats observés. J’étais volontairement lourd dans ma description.
J’aurais pu écrire « si ce que la machine voit est un chat », mais cela aurait été inexact et probablement faux.
Et nous voilà au deuxième point.
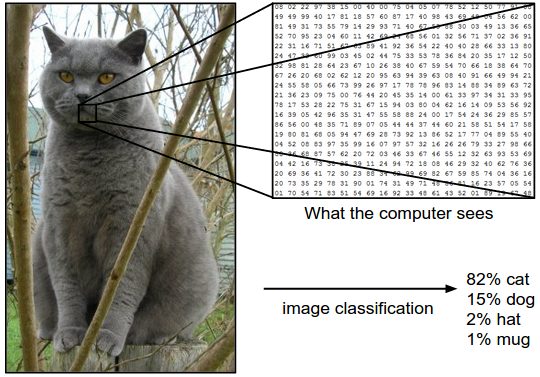
On peut se demander si les machines « voient » ou « savent ». Ce qu’elles font, c’est exécuter une série de règles mathématiques et logiques.
Certes, celles-ci sont souvent inspirées et informées par les modèles mathématiques de la perception et du raisonnement humains.
Cependant, on ne sait toujours pas si ces modèles sont valides, vrais, exhaustifs et uniques – toutes les caractéristiques nécessaires pour fournir des descriptions correctes de la réalité.
Les images inclinées sont des agents perturbateurs connus et remettent en question l’idée de la « compréhension » : à moins d’être prise en compte lors du développement initial de l’algorithme, l’inclinaison d’un objet de certains degrés peut entraîner une mauvaise classification.
Enfin, il y a la question de la causalité. Sans relation causale entre les entrées et les sorties, il est extrêmement compliqué de faire la distinction entre les causes, les effets et les fausses connexions.
Il est également impossible de spéculer sur « pourquoi » d’un résultat et de tester l’effet de différentes interventions (analyse contrefactuelle). Il en résulte une mauvaise explicabilité des résultats et d’autres incertitudes.
Parce que le débat philosophique autour de la causalité est extrêmement riche et varié, je limite la présente discussion à une définition de travail qui peut s’appliquer aux algorithmes d’IA.
Si nous pouvons décrire deux (ou plusieurs) phénomènes du monde réel avec des variables mathématiques et dire qu’une variable est fonction de l’autre, nous pouvons alors dire qu’un phénomène provoque l’autre. Les deux sont causalement liés.
Valider la relation fonctionnelle est l’objectif principal de la science, c’est-à-dire tester des hypothèses alternatives, vérifier les prédictions dans des cas invisibles, mettre l’accent sur des exemples contrefactuels.
Au contraire, si nous observons que les deux variables se comportent de manière similaire, mais qu’il reste des questions ouvertes sur l’interférence d’autres variables, ou que leur inter-relation est inconnue ou douteuse, nous ne pouvons que conclure que les deux sont corrélées.
La corrélation est beaucoup plus faible que la causalité. Il ne peut que nous dire « comment » les variables évoluent, sans faire allusion au « pourquoi ».
La fausse corrélation est un cas classique de corrélation observée qui doit être complétée par une notion intuitive de causalité.
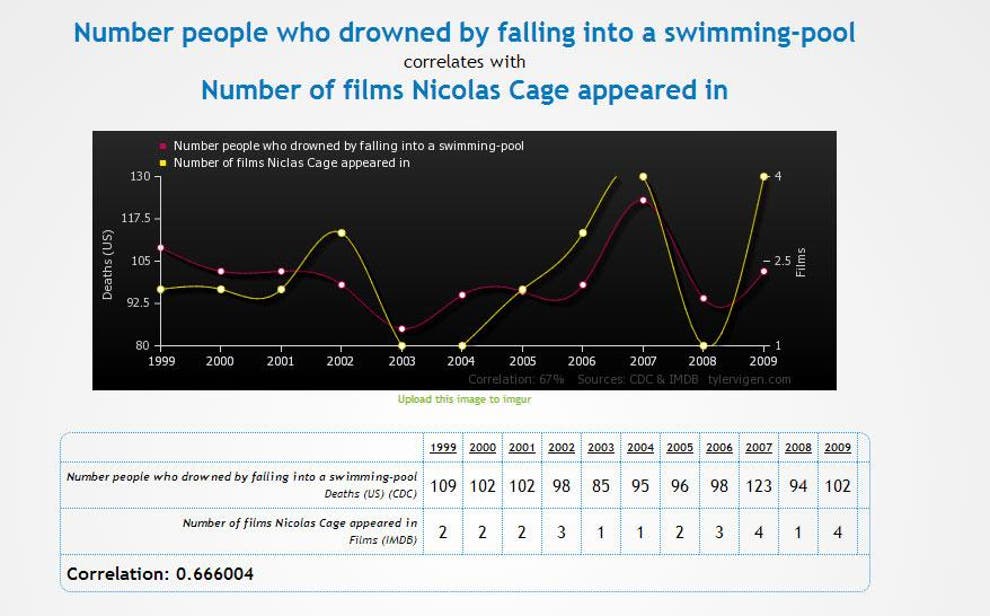
Corrélation entre les films de Nicolas Cage et se noyer dans une piscine
Vous seriez probablement impressionnés par la corrélation extrêment forte entre le nombre de films avec Nicolas Cage et le nombre de personnes qui se sont noyées après être tombées dans une piscine (d’ailleurs, la corrélation est plus élevée que ce qui est observé entre de nombreux effets génétiques et maladies !). Cependant, cela semble absurde.
Pourquoi une personne devrait-elle se noyer après avoir entendu que Nicolas Cage a tourné un film ? Ou, au contraire, M. Cage est-il si cruel de tourner des films après avoir su qu’une personne s’est noyée ? Il y a clairement quelque chose qui ne va pas.
« Clairement » vient de notre notion intérieure de causalité : malgré une évolution similaire, il n’y a aucun moyen que les deux variables soient liées par une relation causale.
Pour résoudre le paradoxe, nous devons invoquer une information supplémentaire, en plus des statistiques pures.
L’inclusion de connaissances causales dans les algorithmes n’est toujours pas au premier plan des débats publics, mais un nombre croissant d’universitaires est concerné.
Certains affirment que sans causalité, nous ne ferions jamais un pas de plus vers une véritable intelligence artificielle : la corrélation statistique à elle seule est tout simplement trop faible et non représentative des schémas de pensée humains.
Certains algorithmes intégrant une telle notion sont en cours de développement, mais ils sont encore en phase préliminaire. Leur promesse est de fournir un pouvoir explicatif, de développer de meilleurs modèles et de permettre des tests contrefactuels (« et si X s’était produit au lieu de Y.. ?”)
La dernière décennie a été caractérisée par un intérêt croissant pour les données et les méthodes basées sur les données. Dans de nombreux cas – la reconnaissance de formes, la classification d’images, et la génération d’art – ces algorithmes peuvent générer automatiquement des résultats très similaires à ceux des humains, attirant ainsi des activités productives et la perception du public sur leur potentiel.
Compte tenu de leurs prouesses croissantes, on peut se demander « dans quelle mesure pouvons-nous les utiliser pour prendre des décisions et en assumer la responsabilité ? »
Selon ce qui a été discuté ci-dessus, à un degré assez faible.
L’analyse des données et les algorithmes sont incroyables pour accomplir des tâches connues, pour démêler des connexions potentiellement utiles, pour informer, pour fournir de nouveaux éléments à discuter, pour stimuler des hypothèses. Mais…
[l’algorithme et l’analyse des données] présentent de graves limitations lorsqu’ils sont utilisés pour la prise de décision automatisée.
C’est un choix humain d’accepter une sortie de probabilité et de s’occuper des corrélations suggérées.
Et, parce que les humains sont capables de créer et de justifier des relations causales, ils devraient en assumer la responsabilité.
Coach Southgate offre un exemple. Il a pleinement reconnu le potentiel des données et des algorithmes, il les a utilisés pour informer la liste des tireurs de penalty, mais il n’a pas reculé lorsque la stratégie a échoué.

nella foto: Gareth Southgate-Bukayo Saka
Il a pris la responsabilité du choix. Dans des scénarios incertains et fluides, où les « prévisions parfaites » n’existent pas, les statistiques passées sont utiles pour construire une base de décision – mais l’intuition humaine et le sens des responsabilités ne sont pas encore prêts à prendre le dessus.

Daniele Proverbio holds a PhD in computational sciences for systems biomedicine and complex systems as well as a MBA from Collège des Ingénieurs. He is currently affiliated with the University of Trento and follows scientific and applied mutidisciplinary projects focused on complex systems and AI. Daniele is the co-author of Swarm Ethics™ with Katja Rausch. He is a science divulger and a life enthusiast.
-

In our first article of two, we have challenged traditional normativity and the linear perspective of classical Western ethics. In particular, we have concluded that the traditional bipolar category of descriptive and prescriptive norms needs to be augmented by a third category, syngnostic norms.