Questo articolo è stato tradotto in maniera completamene automatica. Virtuosismi ed errori nella traduzione sono prodotti da un software.
A quanto può spingersi l’automazione?
Il caso studio:
la traduzione automatica

Non saranno certamente come infilarsi il pesce di Babele nell’orecchio, ma gli algoritmi di traduzione automatica stanno migliorando sempre di più. I giganti della tecnologia (Google, Nvidia e co.), affiancati da un nutrito gruppo di agguerrite startup (su tutte, Deepl, con cui è stato tradotto questo articolo) stanno investendo tempo, energie e risorse per la creazione di traduttori linguistici sempre più raffinati. Non si tratta più di dizionari portatili, capaci al massimo di tradurre letteralmente una parola dopo l’altro, ma programmi in grado di mantenere il senso di una frase, addirittura di una battuta.
Il campo di ricerca alla base di questi programmi è il Natural Language Processing. Frutto della collaborazione di informatici, linguisti e umanisti in senso lato, è uno dei campi interdisciplinari che sta facendo la fortuna dell’Intelligenza Artificiale. Alcune delle architetture informatiche più performanti sono infatti nate in questo campo, estendendosi poi al processamento di dati in altre discipline. L’ultimo ritrovato sono i cosiddetti Transformers, strutture informatiche capaci di dare “attenzione” a determinati elementi in una frase, estrapolarne l’importanza e, in linea teorica, ricostruire il contesto dell’intero discorso. Per completezza, va menzionato che, recentissimamente, i Transformers sono stati applicati con successo al processamento di immagini e alla ricostruzione di proteine (meraviglie dell’analisi dati!).
L’elefante nella stanza

I traduttori automatici sono ormai da tempo sull’orlo di essere venduti come sostituti umani, non solo come aiutanti. Una volta arrivati a un certo livello di precisione, dovrebbero – a rigor di logica – essere in grado di soppiantare i traduttori in carne ed ossa in molti compiti, allo stesso modo in cui i chatbot hanno affiancato i centralinisti. Eppure, non si registrano ancora applicazioni su larga scala degne di nota. La maggior parte dei servizi professionali si avvalgono comunque di personale umano per eseguire le traduzioni, o almeno per controllarle.
La ragione, ad oggi, sembra essere prevalentemente la precisione. Facendo una rapida ricerca su siti di diversi fornitori di traduzione, si nota che tutti tendono a rimarcare che le traduzioni eseguite da macchine non sono 100% corrette e necessitano di un intervento umano per raggiugere i livelli richiesti. Eppure, col costante miglioramento degli algoritmi, verrebbe da chiedersi se e quando avverrà il passaggio di consegne.
Non solo un problema di precisione
![]()
Le difficoltà dell’adozione unica di traduttori meccanici non stanno, però, unicamente nella precisione, ma sono difficoltà condivise con la maggior parte delle soluzioni di intelligenza artificiale. Si tratta di fiducia e responsabilità.
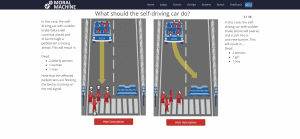
La fiducia sottointende, ovviamente, le aspettative sulla prestazione. Come da un’auto a guida autonoma ci si aspetta determinate prestazioni su strada, da un algoritmo di traduzione si desidera un’accuratezza a livelli umani. Dovrebbe sicuramente azzeccare tutti i vocaboli, ma anche rispettare la sintassi della nuova lingua, le sue strutture lessicali, magari le forme retoriche e, sicuramente, il contesto e i modi di dire. Ma, in senso più generale, manca ancora la fiducia che questi risultati possano venire raggiunti mediante l’analisi di miliardi di testi. Non è del tutto chiaro che schema statistico-induttivo dell’intelligenza artificiale possa riprodurre appieno ciò che un essere umano “sente”, “deduce” o “immagina” – proprio come non si ha ancora una vera e propria definizione per questi termini. Allo stesso modo in cui non traduttore esperto potrebbe non fidarsi di un nuovo arrivato perché “non ha il gioco della lingua”, così potrebbe mantenere riserve verso i traduttori automatici.
Responsabilità per le soluzioni tecnologiche

Il secondo problema è la responsabilità. In altri ambiti applicativi dell’intelligenza artificiale, quella della responsabilità è una difficoltà riconosciuta e dibattuta. Celebre è il caso studio di un’automobile a guida autonoma: dovesse trovarsi di fronte a un dilemma, come prenderebbe e giustificherebbe una decisione? Nel famoso “trolley problem”, un tram destinato a investire cinque persone legate sul binario può essere deviato in un binario parallelo, su cui giace una persona sola: cosa fare? Dilemmi di questo genere – meno sanguinari, forse – possono presentarsi anche in altre applicazioni, come la traduzione automatica. Dovesse venire riconosciuta un’offesa gratuita, la si tradurrebbe fedelmente? O, se fosse impossibile rendere fedelmente una struttura retorica o formale, bisognerebbe segnalare un’allerta, tradurla letteralmente, o procedere comunque? Le conseguenze diplomatiche, commerciali e interpersonali sono ovviamente riconoscibili.
In più, chi sarebbe da ritenere responsabile in caso di errore? L’utilizzatore, reo di non aver sorvegliato accuratamente il programma? L’azienda fornitrice, o i programmatori? Le risposte stentano ad arrivare per campi applicativi più sviluppati (almeno a livello di mercato o a livello mediatico, come le auto a guida autonoma), ma dovrebbero venire cercate in maniera generale, in particolare nel momento in cui le tecnologie dovessero uscire dalle loro nicchie tecnologiche e venissero utilizzate su larga scala e nei contesti più disparati.
Per concludere

La questione di come approcciarsi ai prodotti di algoritmi automatici esula gli esempi più famosi e lampanti e permea ogni campo di applicazione. Sebbene apparentemente innocui e ricchi di promesse, anche i traduttori automatici non sono al riparo da difficoltà dovute alla fiducia traballante e ai vuoti di responsabilità che ancora esistono.
Come anticipato, questo articolo è stato tradotto meccanicamente da un originale in un’altra lingua. Dopo la traduzione, volutamente non è stato ricontrollato e corretto. Dovessero esserci errori o sorgere incomprensioni, l’autore (e la House of Ethics; Nota dell’editore) si assume la responsabilità del proprio esperimento e sarà felice di rispondere alle domande dei lettori.
Cet article a été traduit de manière entièrement automatique. Les virtuosités et les erreurs de traduction sont produites par les logiciels.
Jusqu’où l’automatisation peut-elle aller ?
L’étude de cas :
la traduction automatique
Ce n’est peut-être pas comme mettre le poisson de Babel dans votre oreille, mais les algorithmes de traduction automatique s’améliorent de plus en plus. Les géants de la technologie (Google, Nvidia et consorts), flanqués d’un grand nombre de start-ups féroces (surtout Deepl, avec laquelle cet article a été traduit) investissent du temps, de l’énergie et des ressources dans la création de traducteurs linguistiques toujours plus raffinés. Il ne s’agit plus de dictionnaires portables, capables au mieux de traduire littéralement un mot après l’autre, mais de programmes capables de conserver le sens d’une phrase, voire d’une blague.
Le domaine de recherche qui sous-tend ces programmes est le traitement du langage naturel. Fruit de la collaboration entre informaticiens, linguistes et humanistes au sens large, elle est l’un des domaines interdisciplinaires qui fait la fortune de l’intelligence artificielle. Certaines des architectures informatiques les plus performantes sont en fait nées dans ce domaine, s’étendant ensuite au traitement des données dans d’autres disciplines. La dernière invention en date est celle des “transformateurs“, des structures informatiques capables d’accorder une “attention” à certains éléments d’une phrase, d’extrapoler leur importance et, théoriquement, de reconstruire le contexte de l’ensemble du discours. Dans un souci d’exhaustivité, il convient de mentionner que, très récemment, les transformateurs ont été appliqués avec succès au traitement des images et à la reconstruction des protéines (merveilles de l’analyse des données !).
L’éléphant dans la pièce
Les traducteurs automatiques sont depuis longtemps sur le point d’être vendus comme des remplaçants de l’homme, et non comme de simples assistants. Lorsqu’ils auront atteint un certain niveau de précision, ils devraient – logiquement – être en mesure de supplanter les vrais traducteurs dans de nombreuses tâches, de la même manière que les chatbots ont supplanté les opérateurs téléphoniques. Pourtant, il n’existe pas encore d’applications notables à grande échelle. La plupart des services professionnels font encore appel à du personnel humain pour effectuer les traductions, ou du moins pour les vérifier.
La raison, jusqu’à présent, semble être principalement la précision. Une recherche rapide sur les sites web de divers prestataires de services de traduction révèle qu’ils ont tous tendance à souligner que les traductions automatiques ne sont pas correctes à 100 % et qu’elles nécessitent une intervention humaine pour atteindre les normes requises. Pourtant, alors que les algorithmes continuent de s’améliorer, on peut se demander si et quand le passage de témoin aura lieu.
Pas seulement un problème de précision
![]()
Les difficultés liées à l’adoption d’un modèle unique de traducteur mécanique ne résident toutefois pas uniquement dans la précision, mais sont des difficultés partagées par la plupart des solutions d’intelligence artificielle. Il s’agit de la confiance et de la responsabilité.
La confiance est bien sûr subordonnée aux attentes en matière de performances. Tout comme on attend d’une voiture à conduite autonome qu’elle soit performante sur la route, on attend d’un algorithme de traduction qu’il soit précis au niveau humain. Il doit certainement avoir tous les mots justes, mais il doit aussi respecter la syntaxe de la nouvelle langue, ses structures lexicales, peut-être ses formes rhétoriques, et certainement son contexte et ses idiomes.
Mais, d’une manière plus générale, on ne croit toujours pas que ces résultats puissent être obtenus par l’analyse de milliards de textes. On ne voit pas très bien quel schéma statistico-inductif d’intelligence artificielle peut reproduire intégralement ce qu’un être humain “ressent”, “déduit” ou “imagine” – tout comme on ne dispose pas encore d’une définition correcte de ces termes. De la même manière qu’un traducteur non expert peut ne pas faire confiance à un nouveau venu parce qu’il “n’a pas le sens de la langue”, il peut aussi avoir des réserves à l’égard des traducteurs automatiques.
Responsabilité des solutions technologiques
Le deuxième problème est la responsabilité. Dans d’autres domaines de l’intelligence artificielle, la question de la responsabilité est une difficulté reconnue et débattue. Le cas d’une voiture à conduite autonome est célèbre : si elle était confrontée à un dilemme, comment prendrait-elle et justifierait-elle une décision ? Dans le célèbre “problème du trolley”, un tramway destiné à écraser cinq personnes attachées sur la voie peut être détourné vers une voie parallèle, sur laquelle une seule personne est allongée : que faire ? De tels dilemmes – moins sanglants, peut-être – peuvent également se poser dans d’autres applications, comme la traduction automatique. Si une infraction gratuite est reconnue, sera-t-elle fidèlement traduite ? Ou, s’il était impossible de rendre fidèlement une structure rhétorique ou formelle, faudrait-il donner l’alerte, la traduire littéralement ou procéder quand même ? Les conséquences diplomatiques, commerciales et interpersonnelles sont évidemment reconnaissables.
En outre, qui serait tenu responsable en cas d’erreur ? L’utilisateur, coupable de ne pas avoir suivi attentivement le programme ? Le fournisseur, ou les programmeurs ? Les réponses sont difficiles à trouver pour des champs d’application plus développés (au moins au niveau du marché ou des médias, comme les voitures à conduite autonome), mais elles doivent être recherchées de manière générale, en particulier lorsque les technologies sortent de leurs niches technologiques et sont utilisées à grande échelle et dans les contextes les plus divers.
En conclusion
La question de savoir comment aborder les produits algorithmiques automatisés va au-delà des exemples les plus célèbres et les plus flagrants et imprègne tous les domaines d’application. Bien qu’apparemment inoffensifs et pleins de promesses, même les traducteurs automatiques ne sont pas à l’abri de difficultés en raison de l’instabilité de la confiance et des lacunes en matière de responsabilité qui subsistent.
Comme prévu, cet article a été traduit mécaniquement à partir d’un original dans une autre langue. Après la traduction, elle n’a délibérément pas été vérifiée et corrigée. En cas d’erreurs ou de malentendus, l’auteur ( et la House of Ethics; note de la rédaction) assume la responsabilité de son expérience et sera heureux de répondre aux questions des lecteurs.

Daniele Proverbio holds a PhD in computational sciences for systems biomedicine and complex systems as well as a MBA from Collège des Ingénieurs. He is currently affiliated with the University of Trento and follows scientific and applied mutidisciplinary projects focused on complex systems and AI. Daniele is the co-author of Swarm Ethics™ with Katja Rausch. He is a science divulger and a life enthusiast.
-

In our first article of two, we have challenged traditional normativity and the linear perspective of classical Western ethics. In particular, we have concluded that the traditional bipolar category of descriptive and prescriptive norms needs to be augmented by a third category, syngnostic norms.