[original text in English]
Il existe plusieurs manières d’obtenir une «intelligence artificielle» (IA), et chacune est associée à degrés de contrôle et de prévisibilité différents, avec des implications éthiques immédiates.
Pour commencer: cette «intelligence», ces «intelligences»
Le reste de l’article s’appuie sur la définition de «l’intelligence» comme «la capacité de résoudre des tâches non triviales». Pour le moment, nous ne cherchons pas davantage ce que pourrait signifier «non trivial», mais nous laissons cela à l’intuition du lecteur.
Non seulement cela permet à l’article d’être plus court que quatre monographies, mais cela reflète également le manque actuel de définition précise et partagée à l’échelle mondiale, de ce concept. De la même manière, nous nous limitons à considérer une définition de travail de l’intelligence plutôt que de poursuivre une définition globale – qui n’existe sans doute pas encore.

À partir de l’état actuel de l’art informatique, il existe environ trois méthodes pour créer quelque chose qui satisfait à la définition ci-dessus de l’IA:
3 méthodes pour créer une AI
- fournir des instructions étape par étape;
- énoncer un objectif recherché et exiger «l’intelligence» pour se rapprocher le plus possible, compte tenu de ses capacités;
- ordonner à de nombreuses unités simples d’exécuter des tâches insignifiantes et de coopérer, de sorte que la solution de la tâche non triviale «émerge» du comportement collectif.
Par conséquent, d’un point de vue pratique, nous parlons d ‘«intelligences artificielles».
Non seulement marquent-elles le périmètre de ce qu’il est actuellement possible de créer – et de débattre -, mais elles sont associés à des implications différentes pour la société. Regardons-les.
L ‘«intelligence» procédurale
La première méthode, bien que parfois négligée, reste la plus courante: elle correspond à la manière «classique» de la programmation procédurale.
Pour obtenir des algorithmes «intelligents», les informaticiens programment des règles explicites qui sont ensuite exécutées.
Habituellement, ils correspondent à peu près à de longues chaînes de «si… alors fais… sinon fais…». Un exemple pourrait être «si ces symboles chinois sont fournis, alors renvoyez cette réponse».
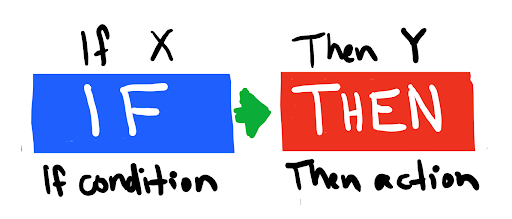
Par conséquent, ils indiquent «comment» atteindre l’objectif, mais laissent le «quoi» comme résultat. Pour obtenir des IA complètes, il est en principe demandé que les programmeurs soient capables de prévoir toutes les instances possibles que le programme est susceptible de rencontrer.
Étant donné l’énorme bibliothèque d’actions, un spectateur tiers ne pourrait pas être en mesure de distinguer une intelligence en codage fort d’une véritable intelligence.
L’avantage d’une telle méthode est son haut niveau de prévisibilité, ce qui facilite le contrôle des résultats. Cela comporte des conséquences sur la responsabilité des comportements indésirables.
Machine Learning et Deep Learning: la tendance en IA
La deuxième méthode comporte la tendance actuelle de l’IA: Machine Learning (ML), Deep Learning (DL) et tout ce qui leur est directement associé.
ML et DL sont reconnaissables par l’absence de règles explicites. Ce qui est demandé à l’algorithme est d’approximer une sortie souhaitée, étant donné plusieurs données d’entrée, en suivant des procédures informatiques et mathématiques.
La manière comment c’est réalisé de manière générique, et comment cela correspond à ce que nous savons du cerveau humain, sera discuté dans des articles ultérieurs. Le point clé est qu’il n’y a pas d’instructions explicites données, mais un objectif défini.
La procédure de programmation consiste à insister sur «ce qu’il faut réaliser» plutôt que sur «comment y parvenir».
Il existe une sous-différence entre ML et DL, en ce que le premier est initialement guidé par une sélection humaine de «caractéristiques» notables (caractéristiques des données ou propriétés statistiques), alors que le dernier a la pleine capacité de sélectionner les caractéristiques par lui-même.

L’avantage immédiat de cette méthode est son étonnante flexibilité lors du traitement de nouvelles observations, ainsi que sa capacité à renvoyer des connexions statistiques entre des caractéristiques qui pourraient être nouvelles pour les observateurs humains.
D’un autre côté, étant donné que «comment atteindre l’objectif» est moins contrôlé, il est généralement compliqué d’argumenter la «raison pour laquelle» un certain produit est livré.
Il existe actuellement deux directions de recherche contrastées: l’une essaie de rendre les algorithmes plus transparents et explicables, l’autre reconnaît de plus en plus de biais dans leurs sorties – principalement, mais pas seulement, liées aux données d’entrée.
Malgré les progrès récents, on ne sait toujours pas si et quand ces problèmes seront résolus de manière satisfaisante.
Des conséquences éthiques immédiates découlent de ces faits: pouvons-nous prédire, dans n’importe quelle situation, le résultat d’un algorithme?
Qui est responsable des comportements indésirables? Devrions-nous continuer à mettre à jour les algorithmes avec de nouvelles données, même après leur mise sur le marché? Les machines supportées par de tels algorithmes pourraient-elles avoir des droits, étant donné qu’elles pourraient être associées à une sorte de conscience?
Intelligence «émergente» et collective
La troisième méthode est peut-être la moins connue du grand public. Son idée de base repose sur la notion d ‘«intelligence collective et émergente», et son inspiration provient majoritairement des essaims.
C’est la méthode des systèmes multi-agents, qui est presque aussi ancienne que celle du Machine Learning.

Le raisonnement sous-jacent est le suivant: de nombreux systèmes complexes affichent des comportements riches et variés lorsqu’ils sont étudiés dans leur ensemble, au niveau de la population, bien que les unités individuelles soient plutôt simples et mécaniques.
En se référant à l’exemple de l’essaim d’insectes, il est bien connu que les acariens individuels ne possèdent pas des niveaux d’intelligence spectaculaires, mais toute la colonie est capable de s’auto-coordonner et de construire des architectures impressionnantes.
Les systèmes multi-agents sont ainsi composés d’unités de calcul uniques – les agents – intégrées dans une colonie. Chaque agent peut être arbitrairement complexe dans sa programmation interne, allant de ceux purement réactifs («si cela est observé, alors faites-le»), à des schémas de traitement qui imitent ce que supposent les psychologues cognitifs (par exemple, la croyance-intention-désirée ( Architecture BDI)). De plus, les agents sont associés à un nombre variable d’autres agents avec lesquels ils peuvent interagir.
La riche dynamique qui émerge de telles interactions conduit à la solution éventuelle de «tâches non triviales» comme le contrôle du trafic aéroportuaire, la gestion des enchères ou le contrôle distribué par robot.
Bien que potentiellement extrêmement polyvalente, cette méthode est sujette à l’existence-même de comportements émergents, qui pourraient être moins prévisibles et pourraient diverger de la sortie souhaitée dans des environnements inconnus.
Cela favorise de nouvelles questions éthiques liées au concept d’émergence, de prévisibilité et de contrôle, et de la dichotomie individu / collectif.
Alors, à quoi sommes-nous confrontés aujourd’hui?
Les trois méthodes peuvent bien sûr être combinées pour développer davantage des systèmes complexes, polyvalents – mais sans doute moins prévisibles.
Cependant, une question pratique pour gérer l’éthique et la réglementation pourrait être: «à quel type de système sommes-nous confrontés»?
Pour autant, nous avons décrit une «approche ascendante» pour parler de l’IA: faire face à une page noire et décider de la méthode à utiliser pour développer un système intelligent.
Au contraire, il pourrait être extrêmement difficile de faire face à un système inconnu et d’en déduire son architecture qui, comme décrit ci-dessus, peut avoir des conséquences différentes pour l’éthique et la législation.
Pour un débat fructueux sur les impacts à court / moyen terme de ces technologies, une meilleure compréhension de leurs méthodes sous-jacentes est donc recommandée.

Daniele Proverbio holds a PhD in computational sciences for systems biomedicine and complex systems as well as a MBA from Collège des Ingénieurs. He is currently affiliated with the University of Trento and follows scientific and applied mutidisciplinary projects focused on complex systems and AI. Daniele is the co-author of Swarm Ethics™ with Katja Rausch. He is a science divulger and a life enthusiast.
-

In our first article of two, we have challenged traditional normativity and the linear perspective of classical Western ethics. In particular, we have concluded that the traditional bipolar category of descriptive and prescriptive norms needs to be augmented by a third category, syngnostic norms.